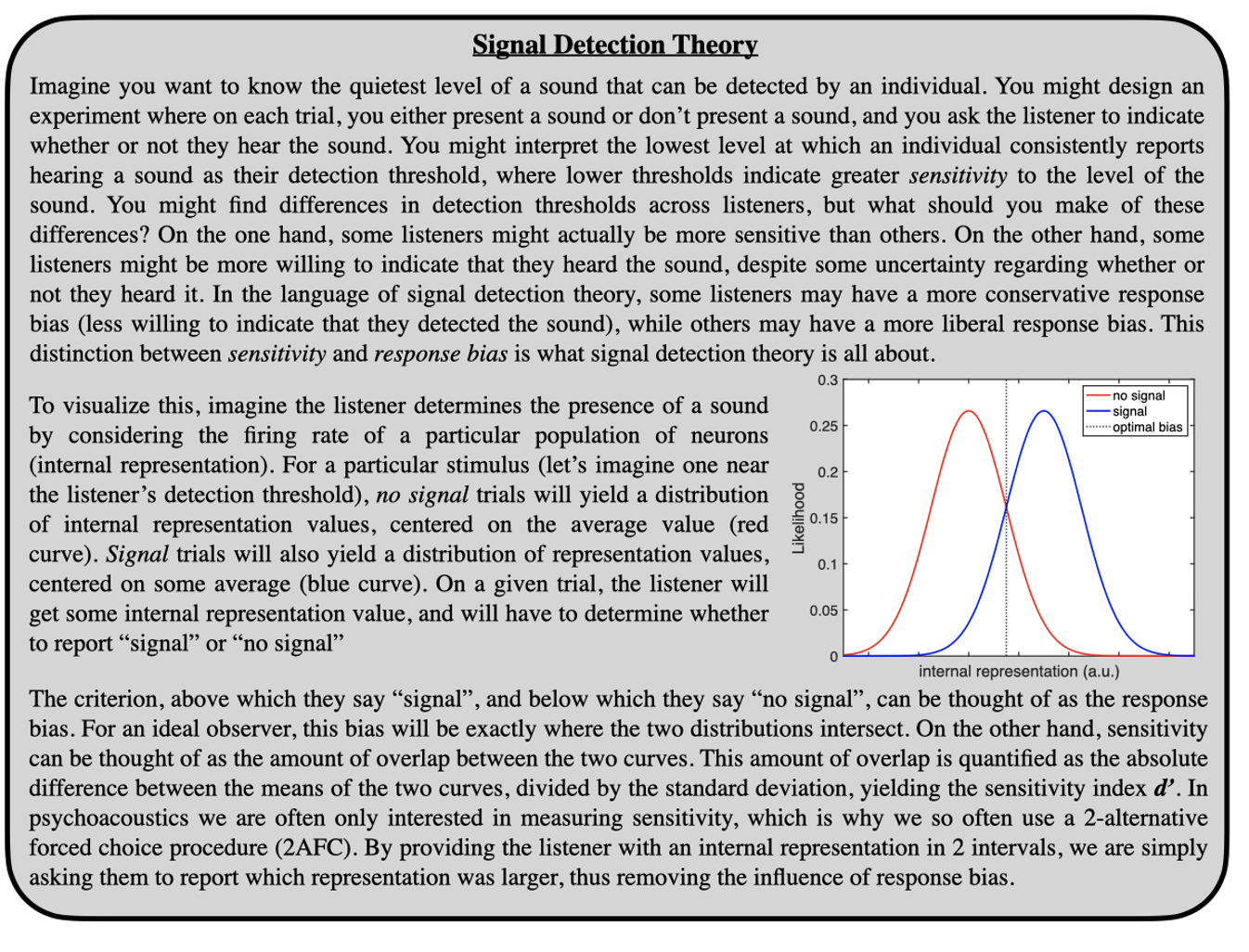
Psychoacoustics is the study of how sounds are perceived. With roots in physics and engineering, traditional psychoacoustics considers the physiological structures that support sound perception as functions that take some input and return some output. While these functions are implemented biologically, it is not the implementation per se that is being studied, but the computation or transformation described by the function (as we shall see though, the perception of sound is ultimately constrained by the biological structures that support sound perception). In order to determine the behavior of these functions, sounds are presented to individuals, and behavioral responses are recorded. In what follows, we will discuss a few core aspects of auditory perception addressed by psychoacousticians, and will cover some of the experimental techniques used to observe and quantify these aspects.
- Peripheral Processing
When a sound is emitted from a source, pressure waves travel away from that source. A sound is perceived as sound by an individual if the pressure waves result in a deflection of the eardrum (tympanic membrane). The power transferred from the air to the tympanic membrane must then be transferred to the fluid-filled cochlea. This is done through a series of middle ear bones (ossicles) that amplify this power and focus it on a much smaller membrane (oval window) at the base of the cochlea. The cochlea is a spiral structure embedded in the temporal bone, and contains three fluid-filled ducts (a vestige of our aquatic evolutionary origins). Pressure is applied externally to the oval window, and having entered the cochlea, must ultimately be transduced into a neural signal. This is accomplished by hair cells in the organ of Corti, which are tethered to the tectorial membrane. Pressure waves in the cochlea result in vibration of the basilar membrane at the base of the organ of Corti, which results in a shearing motion of the tethered (inner) hair cells. This shearing motion leads to depolarization of the hair cell, which results in the firing of an action potential. Hair cells are enervated by auditory nerve fibers, which carry information to the cochlear nucleus, and through a cascade of brainstem and midbrain structures, information is carried to the primary auditory cortex. Critically, a width and stiffness gradient in the basilar membrane allows vibrations at particular frequencies to resonate at specific locations along the basilar membrane. Higher-frequency sounds resonate at the base of the cochlea, while lower-frequency sounds resonate at the apex of the cochlea. This tonotopic organization is critical for our perception of sounds. Interestingly, psychoacousticians have long observed that low-frequency tones are more effective at masking high frequency tones than vice versa, a phenomenon called “upward spread of masking”. This is because the vibration pattern in the cochlea for a sound at a particular frequency is asymmetric, with a much longer tail extending at higher frequencies (this asymmetry can help explain why age-related hearing loss tends to affect higher frequency regions of the cochlea).
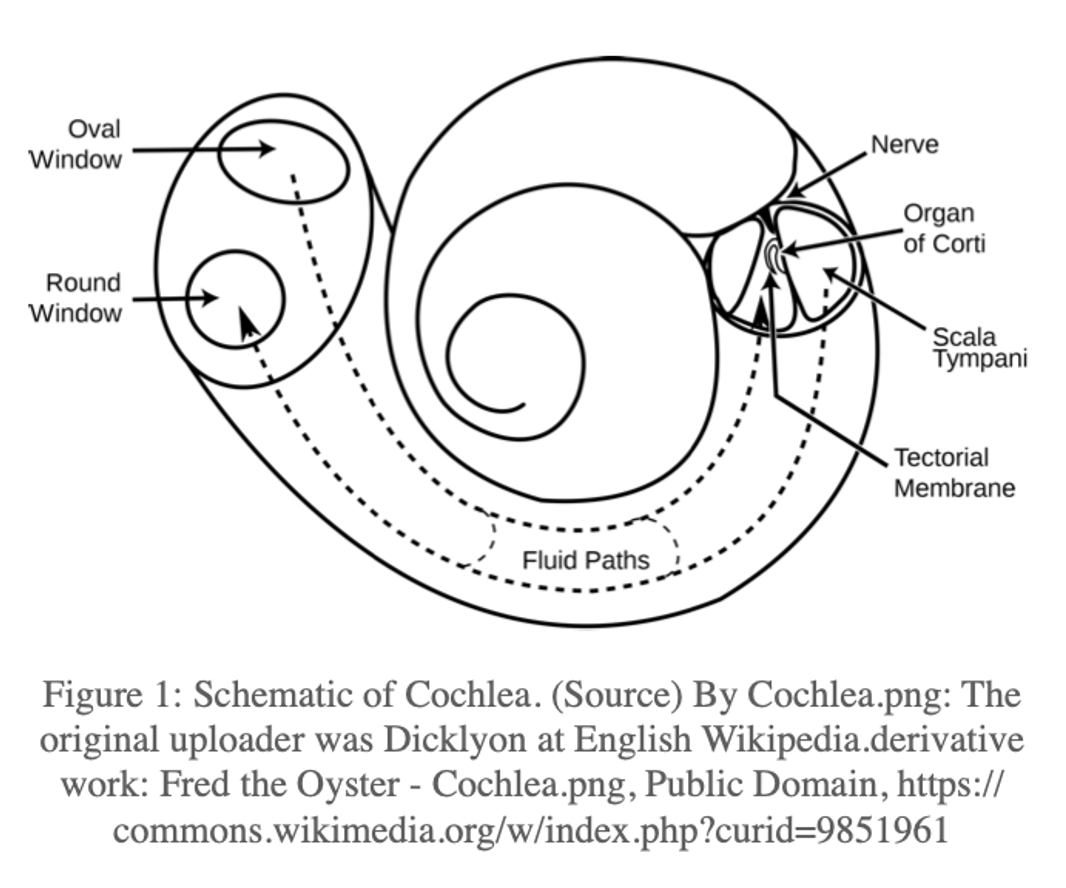
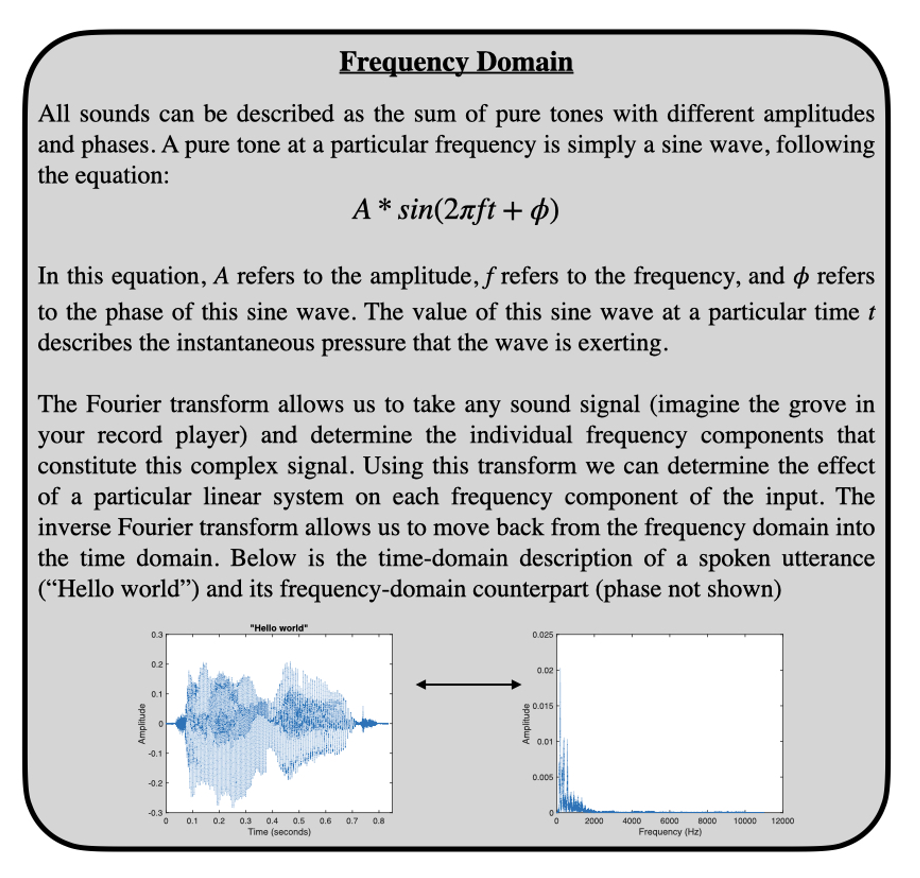
While psychoacousticians are not necessarily concerned with the biology of these structures, there are significant transformations of the input sound signal that occur when passing through these structures. When sound passes through a (linear) system or structure, the transformation of that sound can be described by a filter (or transfer function). This transfer function can be described in the time domain or the frequency domain (see “Frequency Domain” box). To reach the tympanic membrane, the source sound is filtered by the external ear, which means that certain frequencies present in the sound source may be attenuated while others may be amplified. Likewise, to reach the oval window, the sound at the tympanic membrane is filtered by the middle ear. Like any acoustic amplification system you might purchase for your home theater, the physical components that allow sound to be captured and amplified themselves act as filters on the original sound. In the case of both electronic and physiologic sound amplification systems, the influence of these filters can be important to consider when describing how sounds are ultimately perceived. However, it is worth pointing out that the goal of our hearing sense organ is to allow us to make use of sounds in our environment to further our evolutionary interests. It is interesting to consider then whether the particular shapes of our external and middle ear filters are in service of some auditory behavior, or simply reflect physical limitations on the veridical transmission of acoustic information to the nervous system. In other words, why is your ear shaped the way it is?
In the cochlea itself, the incoming pressure wave corresponding to the sound source is filtered into overlapping band-pass filters corresponding to its tonotopic organization (the activity of the outer hair cells actually make this filtering process non-linear, though a discussion of cochlear non-linearities is beyond the scope of this entry). This concept of cochlear filtering is central to psychoacoustics, though it remains controversial. There are two reasons for this controversy. First, our understanding of the shapes/bandwidths of these filters in humans have come from behavioral studies, and since behavior ultimately reflects the entire auditory system, it is difficult to determine whether the filter shapes we derive with psychoacoustic methods reflect cochlear filtering or filtering at some higher level of auditory processing. It is therefore common to refer to the bandpass filters measured behaviorally in humans as “auditory” filters (or psychophysical tuning curves). Second, despite the bandpass filtering that occurs, temporal aspects of the filtered sounds are represented in the firing rate of auditory nerve fibers. The extent to which this temporal information is used for the perception of sound is still debated.
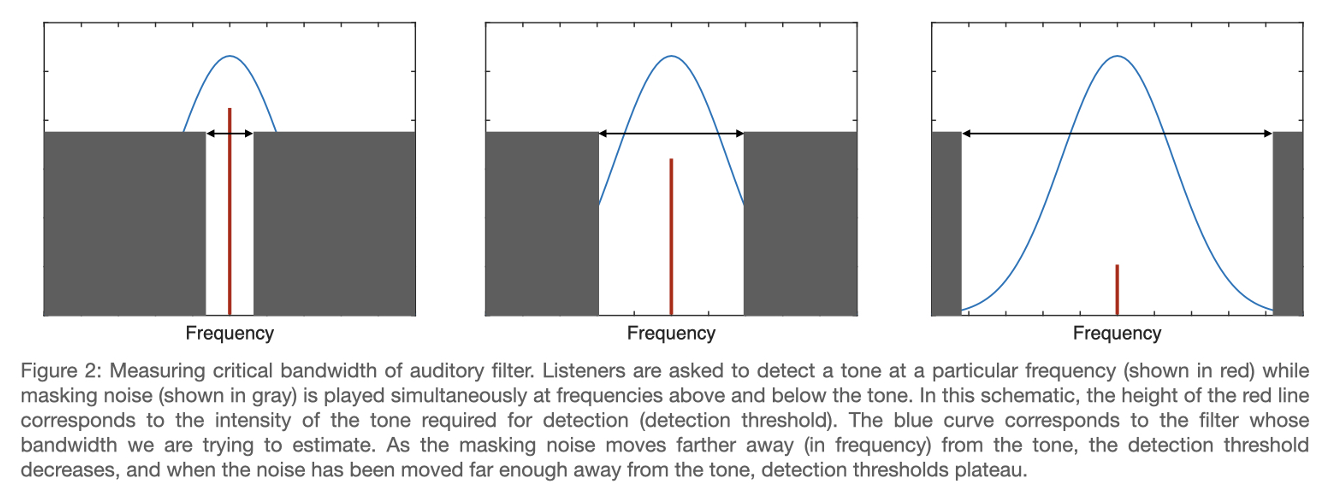
To illustrate this controversy, we will consider a classic psychoacoustic method to determine the bandwidth of an auditory filter (critical bandwidth). Shown in Figure 2, auditory filter bandwidths are estimated by asking listeners to detect a tone in the presence of masking noise. Detection is measured using a 2-alternative forced choice procedure (see “Signal Detection Theory” box), where a stimulus is played sequentially in two intervals. While the masking noise is presented in both intervals, the target tone is only presented in one of these intervals, and the listener is asked to indicate which interval contained the tone. As the masking noise is moved farther away from the tone in frequency, the detection threshold for the tone decreases. This is because less noise is passing through the same filter that the tone is passing through. At a large enough separation, the noise no longer masks the tone at all, which means that the bandwidth of the filter is narrower than this separation.
The core assumption of this method is that listeners detect the presence of a tone by considering the firing rate of neurons enervating a particular auditory filter. This is referred to as the “rate-place” code for auditory perception (firing rate corresponding to a particular location along the cochlea). If this assumption were true, it would be impossible for listeners to perform this task if the overall presentation level of the stimulus was varied at random in each interval. This is because “roving” the presentation level renders absolute firing rate as an unreliable cue. It has been repeatedly demonstrated that tones in the presence of masking noise can be reliably detected despite introducing random level variation, which means that the core assumption underlying this method is not valid.
How might listeners detect a tone in the presence of masking noise
then? Two alternatives have been proposed: (1) listeners compare rates across different auditory filters, (2) listeners use fluctuation patterns within
a filter. This second alternative raises the possibility that temporal
firing patterns within a filter are critical to auditory perception. As
explained below, there is one auditory behavior that is known to rely on
precise temporal firing patterns: localization of low-frequency sounds
along a left-right axis. However, some psychoacousticians would argue
that a variety of auditory behaviors, up to and including speech
perception (that most uniquely human of auditory behaviors), rely on
temporal firing patterns within
auditory filters themselves rather than a simple rate-place code for each filter.
Psychoacousticians are interested in more than just peripheral transfer functions and auditory filters though. Significant processing occurs subsequent to the cochlea along the ascending auditory pathway. For instance, humans are able to compare information across ears to determine the location of a sound source in space. Also for instance, humans are able to understand speech, the processing of which requires a network cortical structures.
- Binaural Hearing
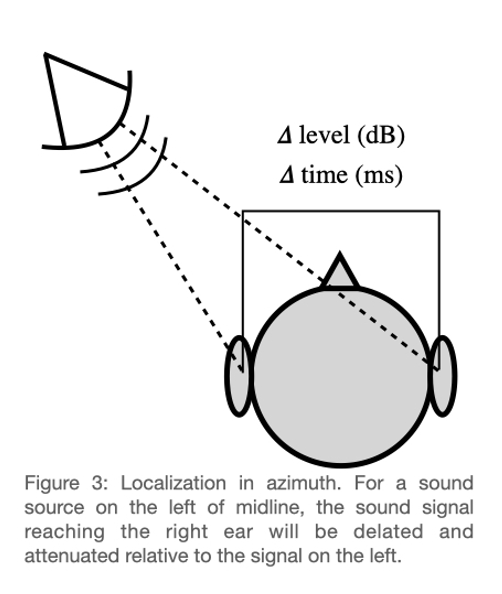
There are three dimensions along which a sound location can vary with respect to the head: left/right, up/down, and near/far. Our ability to localize along the left/right axis (azimuth) is supported by specialized brainstem nuclei that allow us to compare level differences and timing differences across ears. Interaural level differences (ILDs) arise from the fact that the head acts as filter. Imagine a sound source on your left. In order for that sound to reach your right ear, it must travel around your head. In so doing, the intensity of the signal is attenuated, particularly at high frequencies. This “low-pass” characteristic of the head (as filter) is exceedingly common in the natural world, where physical structures in general are more likely to attenuate high frequencies (though these structures also tend to have “resonant” frequencies). Interaural time differences (ITDs) arise from the fact that sound takes time to travel through a medium, and if one ear is closer to the sound source, the signal will arrive at the closer ear first. It is worth noting that the speed of sound is around 343 m/s in air (under standard humidity, temperature, and pressure) and the average human head is around 56 cm. This means that the difference in arrival time across ears is extremely small (< 1 ms), and specialized structures have evolved to compute such small ITDs. Unlike ILDs, which are larger and therefore more salient at high frequencies, ITDs are more salient at low frequencies. This is because at high frequencies, ITDs can become ambiguous. This perceptual result was established long before the underlying physiology was understood, and has to do with the fact that at high frequencies, multiple cycles of the stimulus occur in the time it takes to travel around the head. In other words, it is the interaural phase that is critical, at least for non-transient sounds. Indeed, when the initial onset cue has been experimentally controlled for, we refer to an interaural phase difference (IPD) rather than an ITD. While an involved discussion of “onset” vs “ongoing” ITD/IPDs is beyond the scope of this entry, suffice it to say that this is an active area of research. Like many active research areas in psychoacoustics, this area relies increasingly on our understanding of the physiology supporting the perception in question. As a brief example, it has been observed that ITD/IPDs at the onset of an otherwise unmodulated sound have an increased perceptual salience. This finding can be (mostly) accounted for by the fact that neurons “adapt” when responding to steady sound at a frequency to which the neuron responds. When this sound turns off, adaptation is released. Therefore when a sound turns on after being off, the quality of the neural representation is much better than when a sound has already been playing. This fact of physiology has particularly important consequences for binaural hearing, where a precise temporal representation can be critical for perception.
To localize along the up/down axis (elevation), listeners consider the spectral shape of the sound arriving at the ear. The first part of the external ear is a cartilage extremity called the pinna, which has a strange ridged shape whose evolutionary function may not be obvious. It is not strictly cone- or arc-shaped as you might expect if its only job was to catch sound waves. It turns out that the ridged pattern introduces a unique pattern of dips and peaks into the spectrum for sounds at different elevations. Like ILDs, the filtering that the pinna does to sounds at different elevations is more salient at high frequencies. To convince yourself of the importance of the pinna in supporting sound localization in elevation you can have a friend sit down and close their eyes. Take out your key ring and jangle it at various elevations in front of your friend, asking them to point to the location. You will find that your friend is pretty good at this. However, if you ask your friend to take their index finder and bend down their pinna, not enough to block their ear canal but enough to distort the shape, you will find that your friend makes surprisingly large errors in elevation-based localization.
When considering localization along the front-back axis (distance), a distinction is usually made between peri-personal and extra-personal space. Because sound follows the inverse-square law (sound intensity is inversely proportional to the square of distance from the source), sound sources close to the listener (peri-personal) have an overall level that depends strongly on distance. Imagine a mosquito buzzing around your head. You can tell that it is getting closer when the buzzing gets noticeably louder. This can be true for sounds that are farther away, but small variations in distance of sound sources in extra-personal space will not yield salient changes in overall level. For sound sources in natural echoic environments, listeners can consider the ratio of the direct sound energy vs reflected sound energy. While this can be difficult to compute with precision, it is generally true that nearby sound sources will have a larger direct-to-reverberant ratio (DRR), and listeners seem to use this cue to determine the distance of a source.
- Speech Perception
While there is not a clear distinction between psychoacoustics and the study of speech perception, speech is an ecologically special acoustic signal with a unique set of neural structures governing its perception. Speech perception can be considered a field of study in its own right, with speech scientists occasionally using psychoacoustic methods to learn about speech-specific mechanisms. On the other hand, psychoacousticians often use speech stimuli to probe more general features of the auditory system. Let’s consider the “cocktail party” problem. In a room full of competing talkers, how do I selectively listen to one particular talker? To conceptualize this problem, we need to introduce a distinction between energetic and informational masking. Energetic masking was discussed above (Figure 2), and refers to the fact that if a masker passes through the same auditory filter at the same time as a target signal, it will be more difficult to detect that target signal (as a visual analogy, imagine trying to determine the shape of an object that is partially or completely hidden behind another object). Informational masking refers to situations when you are building up a representation of a complex auditory object (i.e. a speech stream), and you are not sure which acoustic features belong to that complex object. In the context of the cocktail party, informational masking occurs when bits of acoustic information from non-target talkers get incorrectly incorporated into your representation of the target talker whose message you are trying to understand. As a simple example, imagine you hear the following four words “I am not listening”, with the word not being spoken by a non-target talker. If you the listener incorrectly attribute the word not to the target source, you will have incorrectly understood the message of the target talker, despite a complete absence of energetic masking. While relatively little can be done to overcome energetic masking, there are a number of cues available to overcome informational masking. For example, different talkers will have different vocal tract characteristics, and certain features of this vocal tract are available listeners. In the source-filter model of speech production, vibrations of the vocal folds in the larynx generate a sound source that is filtered through the vocal tract. While this vocal tract filtering can change the spectrum of the original sound source, the fundamental frequency (F0) corresponding to the sound source can be computed. F0 varies across individuals, and may be used to distinguish acoustic energy belonging to one talker vs another. As another example, assuming that the target talker is in a unique spatial location with respect to the competing talkers, binaural cues can be used to determine whether acoustic energy belongs to the target talker. Understanding the acoustic cues that support our ability to “solve” the cocktail party problem is an active area of research, and of interest to those designing signal processing algorithms to improve speech perception in multitasker environments.
The information vs. energetic masking distinction, useful though it is in understanding the cocktail party problem, originated with the study of simple tone patterns. Listeners in this task were asked to detect the presence of a repeating tone sequence at a particular frequency. Masker tones were presented simultaneously with each tone in the tone sequence, and these masker tones were either fixed in frequency or drawn at random. A protected frequency region was defined around the target to minimize energetic masking. When the masker tones were drawn at random, it was easy for the listeners to detect the presence of the target. This is because they could simply listen for the presence of a repeated tone sequence, since the masker, being random, did not resemble the target in this way. However, when the masker was fixed in frequency, performance plummeted, since now listeners had to listen exactly at the correct frequency in order to solve the task.
Textbooks
Blauert J. (1997) Spatial Hearing: The Psychophysics of Human Sound Localization (MIT Press, Cambridge, MA).
Green, D. M. & Swets, J. A. Signal Detection Theory and Psychophysics. (Wiley, Oxford, 1966).
Luce, R. D. (1993). Sound and hearing: A conceptual introduction (Erlbaum, Hillsdale, NJ).
Macmillan, N. A. & Creelman, C. D. (1991) Detection Theory: A User's Guide (Cambridge Univ. Press, New York, NY).
Moore, B. C. J. (2012). An Introduction to the Psychology of Hearing (Academic, London).
Relevant Book Chapters and Journal Articles
Cherry EC. (1953) “Some experiments on the recognition of speech, with one and with two ears,” J. Acoust. Soc. Am. 25:975–979.
Dau, T., Kollmeier, B., and Kohlrausch, A. (1997a). “Modeling auditory processing of amplitude modulation. i. detection and masking with narrow-band carriers,” J. Acoust. Soc. Am. 102, 2892–2905.
Glasberg, B. R., and Moore, B. C. J. (1990). ‘‘Derivation of auditory filter shapes from notched noise data,’’ Hear. Res. 47, 103–138.
Kidd, G., Jr., Mason, C. R., Richards, V. M., Gallun, F. J., and Durlach, N. (2008). “Informational masking” in Auditory Perception of Sound Sources, edited by W. A. Yost (Springer, New York), 143–189.
Levitt, H. (1971). “Transformed up-down methods in psychoacoustics,” J. Acoust. Soc. Am., 49, 467–477.
Lyon, R. F., Katsiamis, A. G., and Drakakis, E. M. (2010a). “History and future of auditory filter models,” in IEEE International Conference on Circuits and Systems , pp. 3809–3812.
Neff, D. L., and Callaghan, B. P. (1988). “Effective properties of multicomponent simultaneous maskers under conditions of uncertainty,” J. Acoust. Soc. Am. 83, 1833–1838
Shera, C. A., Guinan, J. J., and Oxenham, A. J.(2002). “Revised estimates of human cochlear tuning from otoacoustic and behavioral measurements,” Proc. Natl. Acad. Sci. U.S.A. 99, 3318–2232.
Shinn-Cunningham BG. “Object-based auditory and visual attention,” Trends Cogn. Sci. 2008;12:182–186
de Cheveigne´, A., and Kawahara, H. (2002). ‘‘YIN, a fundamental frequency estimator for speech and music,’’ J. Acoust. Soc. Am. 111, 1917– 1930.
Zhang, X., Heinz, M. G., Bruce, I. C., and Carney, L. H. (2001). “A phenomenological model for the responses of auditory-nerve fibers. I. Nonlinear tuning with compression and suppression,” J. Acoust. Soc. Am. 109, 648–670.