A primeira versão do Alfabeto Fonético Internacional (IPA, na sigla em inglês para International Phonetic Alphabet) foi publicada em 1888 pela Associação Fonética Internacional. Embora tenha sofrido modificações ao longo de sua existência mais que centenária, notadamente as feitas pela Convenção de Kiel em 1989, o princípio fundamental é o de que cada símbolo fonético representa um único som, estabelecendo uma relação biunívoca entre som e símbolo, algo que os sistemas ortográficos alfabéticos deixaram de ter ao longo de suas histórias.
A forma de cada símbolo é única e especificada em Unicode de tal forma que seja reproduzida de maneira idêntica sempre que um símbolo for usado. Por exemplo, [ɑ] e [a] representam vogais distintas: o primeiro símbolo é o da vogal baixa posterior não arredondada encontrada no inglês em palavras como hot pronunciada por um nova-iorquino, enquanto o segundo símbolo é o da vogal baixa central não arredondada encontrada no português brasileiro em palavras como "pá".
Transcrever pressupõe a capacidade de discriminar os sons de uma determinada língua, por isso é uma tarefa que deve ser sempre feita por um falante nativo ou com a assistência de um. Erros de transcrição podem advir pelo simples fato de não ouvirmos determinadas distinções. Imagine um espanhol, que não distingue os sons dos "e" aberto e fechado, tentar fazer a transcrição das vogais tônicas das palavras "festa" e "besta", tarefa imediata para um brasileiro que logo dirá que o "e" de "festa" é aberto, enquanto o "e" de "besta" é fechado. Ou ainda, um brasileiro que nunca aprendeu sueco (são muitos), tentar discriminar as 17 vogais dessa língua.
Desde o advento dos programas de software que permitem a análise acústica da fala, transcrever não é só uma questão de bem ouvir, mas também envolve a possibilidade de dirimir dúvidas sobre determinados sons a partir de análises instrumentais contrastivas. Isso se faz necessário porque a percepção sonora envolve um componente chamado de processamento top-down que nos ajuda a reconhecer as palavras em situações de ambiente ruidosos, de hipoarticulacão, entre outros. Esse processamento se serve do conhecimento que qualquer falante nativo de uma língua tem do vocabulário, fazendo inferências a partir do estímulo sonoro. Em parte por conta desse processamento, em parte pelo conhecimento ortográfico, não é fácil perceber que os sons dos dois "a" da palavra "pata" são distintos acusticamente e, por isso, representados por símbolos fonéticos distintos como nesta sequência entre colchetes: [patɐ]. Para se ter uma ideia de como o componente top down de nossa mente funciona, escute a palavra "pata" na frase "Digo pata baixinho" pata aqui, observando que os dois "a" de "pata" parecem o mesmo som. Escute agora as sílabas da palavra separadamente: "pa-" pa e "-ta" ta aqui e perceba como, de fato, não soam da mesma forma. Por isso os símbolos distintos para esses dois "a". Os colchetes delimitam um trecho de transcrição fonética, enquanto as barras inclinadas, a de uma transcrição fonológica. Este verbete só trata aqui do primeiro tipo de transcrição.
Para tomar a decisão acima de que se tratam de dois sons distintos precisamos escutar as sílabas separadamente, algo que pode ser feito facilmente com a ajuda de um software de análise acústica como o Praat. A sílaba é a menor unidade que podemos escutar, porque qualquer tentativa de escutar um som correspondente a um fonema isoladamente gera ilusões auditivas pela quebra de uma informação crucial para o processamento sonoro: a transição entre os elementos constitutivos da sílaba.
Além disso, em caso de dúvida, a composição em frequência de cada um desses sons, ilustrada na Figura 1 abaixo para a palavra "prata", revela que a primeira frequência de ressonância (F1), indicadora da altura da língua, tem valor mais elevado no "a" tônico (770 Hz) do que no "a" pós-tônico (600 Hz), por o segundo sofrer um alçamento nessa posição.
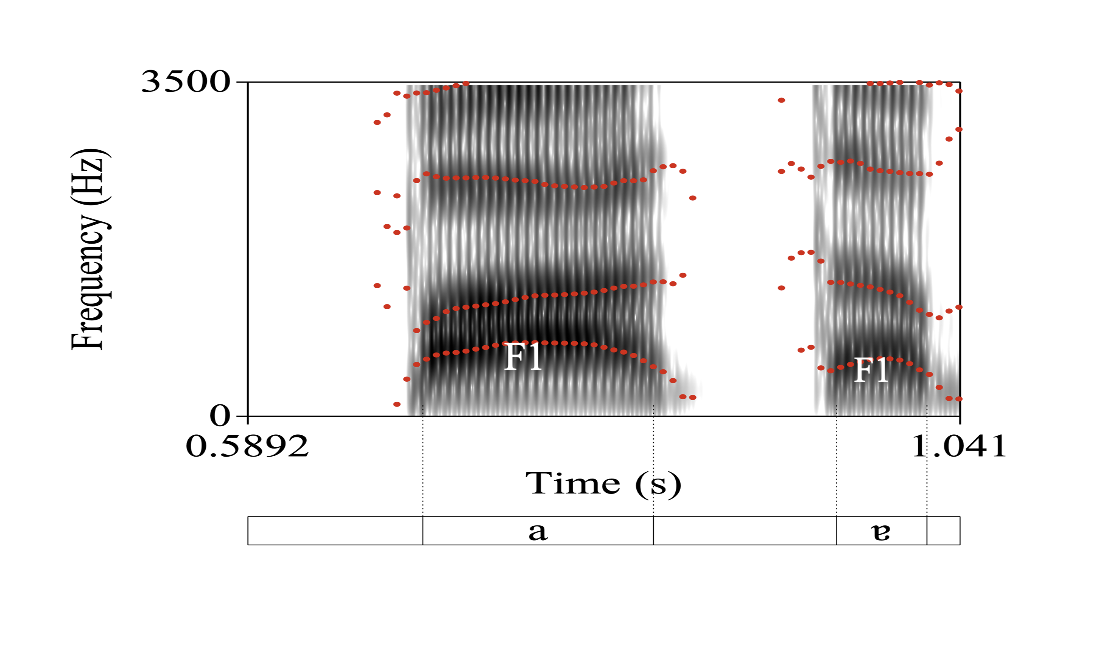
Figura 1: Os dois "a" da palavra "pata" num locutor mineiro adulto.
Com esses cuidados, podemos transcrever foneticamente as vogais do português brasileiro. Vejamos agora contrastes que frequentemente são passados por cima nas transcrições das vogais, como os que existem entre as vogais em posição pós-tônica e as demais, pré-tônicas e tônicas. Já comentamos da transcrição do "a" final de "pata" como [ɐ]. Observe que tanto em português brasileiro quanto em português europeu, esse "a" não tem o grau de alçamento da chamada vogal neutra shwa (símbolo [ə]) que se encontra tanto no inglês quanto no português europeu em palavras como "bate" ou "pegar", mas não ao final de "bata". Assim, não cabe em português brasileiro o uso do símbolo do shwa para vogais pós-tônicas marcada pela ortografia com "a", como mostramos em outro momento (Barbosa, 2012).
O mesmo cuidado se deve ter para distinguir as vogais em contraste da palavra "suco" escutando aqui as sílabas "su- " su e "co" co em separado para constatar que a transcrição da palavra dever ser esta: [sukʊ], com o símbolo final tanto distinto do primeiro "u" quanto do som [o] em "sopa", uma vez que o som [ʊ] é mais próximo de [u], sendo uma forma mais centralizada dele. Essa distinção não se dá quando as átonas precedem a tônica, como em "cuscuz", transcrito como [kuskus].
Para as realizações das vogais em palavras como "cite" deve-se ter o mesmo cuidado, devido a sua distinção em qualidade, transcrevendo-as desta forma: [sitʃɪ]. Em todas as palavras até agora transcritas é possível usar o diacrítico de acento primário ['] para indicar a posição da sílaba tônica logo antes dessa, como em ['sitʃɪ]. Não a usamos até o momento porque a própria distinção da qualidade da vogal em português brasileiro já assinala onde está a tônica de uma palavra apenas com acento primário: a sílaba que precede a primeira sílaba da palavra com um dos símbolos de vogal reduzida [ɪ ɐ ʊ], caso haja uma vogal reduzida. Como exemplos temos: "chácara" ['ʃakɐɾɐ], "jacu" [ʒa'ku], "cisto" ['sistʊ], "casaco" [ka'zakʊ], "Amélia" [a'mɛlɪɐ]. Nenhuma alteração de pronúncia se dá usando ou não o diacrítico de acento primário. Isso não acontece, por exemplo, em italiano, cuja vogal pós-tônica tem qualidade muito próximo à tônica, permitindo até contrastes como "bambine" [bam'bine] vs. "bambini" [bam'bini], palavras que não são pronunciadas normalmente de forma distinta por brasileiros pelo fato de que, em nossa língua, "e" e "i" finais em paroxítonas têm o mesmo som [ɪ] para a maior parte dos nossos falares. No caso do italiano o diacrítico é necessário para distinguir a vogal tônica da átona final, como entre "cita" ['tʃita] e "città" [tʃi'tta].
Voltando ao português brasileiro, átonas pré-tônicas podem ter uma
qualidade vocal de pós-tônica em polissílabos com acento secundário,
como em "macacada", que pode ser pronunciada como [makɐkadɐ] ou como em "fonoaudiólogo", pronunciada como [fonʊɑwdʒiɔlogʊ].
Observe que o /a/ após o morfema "fono" se posterioriza por conta das
vogais posteriores que a cercam, por isso o som se modifica e o símbolo é
alterado em relação à transcrição mais comum
([a]).
Em palavras ou frases isoladas lidas não há grandes variações na produção dos sons. No entanto, em situações mais naturais, deve-se prestar bem atenção e fazer uso de programa de análise acústica para tirar dúvidas sobre a forma de pronúncia de um som ou para saber se ele foi, de fato, realizado. Ouça a palavra "cidade" cidade aqui de uma entrevista informal e perceberá algo muito rápido na primeira sílaba. Se ouvir o trecho entre o início da palavra e o início do primeiro "d" ouvirá isto: ci aqui. Isso mesmo, o "i" não foi produzido e temos esta transcrição: [s'dadʒɪ]. Observe a presença da vogal da primeira sílaba da palavra "cidade" vs. sua ausência nos espectrogramas abaixo, Figura 2.
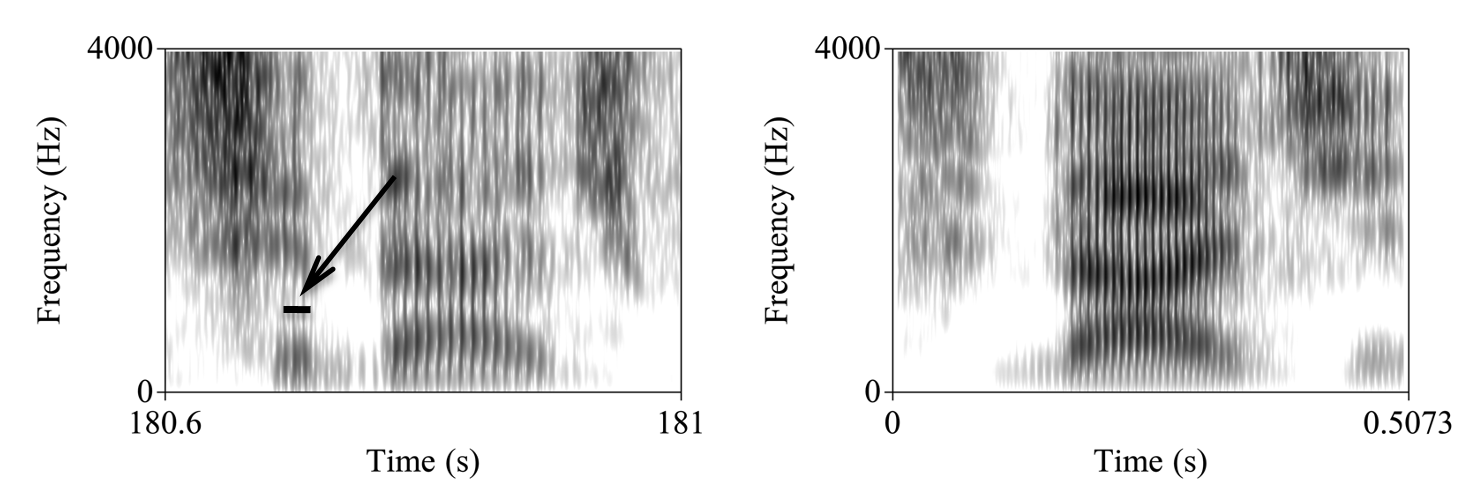
Figura 2: Dois trechos de espectrograma mostrando duas pronúncias da palavra "cidade" pelo mesmo locutor, a da esquerda pronunciando uma curta vogal /i/ na primeira sílaba e a segunda pronunciando apenas a fricativa /s/ da mesma sílaba.
Outro cuidado na transcrição fonética das vogais do português brasileiro é o caso das vogais nasalizadas. Por poderem estar em posição tônica ou pós-tônica, nesse caso se faz necessário o uso do diacrítico de tonicidade. Além desse cuidado, o símbolo adequado para a vogal /a/ nasalizada é [ɐ̃] e não *[ã], em virtude do alçamento da língua por conta da nasalização: compare a posição de sua mandíbula durante a pronúncia do "a" da primeira sílaba de "capa" com a sua posição durante a pronúncia do "a" da primeira sílaba de "cama" para perceber esse alçamento. Por isso a transcrição dessa última palavra é ['kɐ̃mɐ]. Compare casos com ditongos que só diferem quanto à tonicidade, como em "viram" ['viɾɐ̃w̃] vs. "virão" [vi'ɾɐ̃w̃]. Assim, o inventário das vogais nasalizadas é este [ĩ ẽ ɐ̃ õ ũ], vogais que se encontram nas tônicas respectivas de "sinto", "sento", "santo", "sondo" e "sunto" ou nas pós-tônicas respectivas de "ínterim", "hífen" (mas aqui seguido da semivogal nasalizada [j̃]), "ímã", "fóton" e "álbum".
As distinções de grau de abertura das vogais médias que se encontra em pares como "sede" (de água) e "sede" (do clube) é marcada pelo uso de símbolos distintos, respectivamente [e] e [ɛ]. O mesmo vale para o contraste entre as tônicas de "poço" [o] e "posso" [ɔ].
Certamente, especialmente em português brasileiro por conta de encontros de vogais como em "o menino e o amigo", a decisão por considerar que sequências são hiatos e que sequências são ditongos ou tritongos deve receber um cuidado à parte. Nesse caso, o transcritor deve mais uma vez se apoiar em análises acústicas feitas por programas como o Praat. Uma sequência de vogais como em "de ouro" pode ser pronunciada como [dʒi 'oɾʊ] ou [dʒj'oɾʊ] e nem sempre é fácil perceber o que foi dito sem uma análise acústica acurada. Um exemplo da importância da observação espectrográfica para auxiliar a dirimir sobre se houve ou não ditongação nesses casos pode ser feita usando espectrogramas como os da Figura 3, em que se vê a sequência ditongada "de um (poleiro)" à esquerda e a sequência não ditongada "de ou(ro)" à direita. Na forma ditongada, a figura mostra em linha tracejada à esquerda a queda de F2 logo após a pronúncia do "d", característico de uma semivogal, aqui o [j], assinalando uma única sílaba [dʒjũ]. No espectrograma da direita, a vogal da mesma preposição "de" [i], tem seu F2 com o mesmo valor (segmento curto horizontal da figura) por um tempo curto, o que assinala uma sequência de duas sílabas [dʒi o].
Observe com isso o grande aporte para a transcrição fonética do uso de uma ferramenta computacional de análise acústica. Essa ferramenta se mostra muito útil para a transcrição de consoantes. Mas isso é tema de outro verbete.
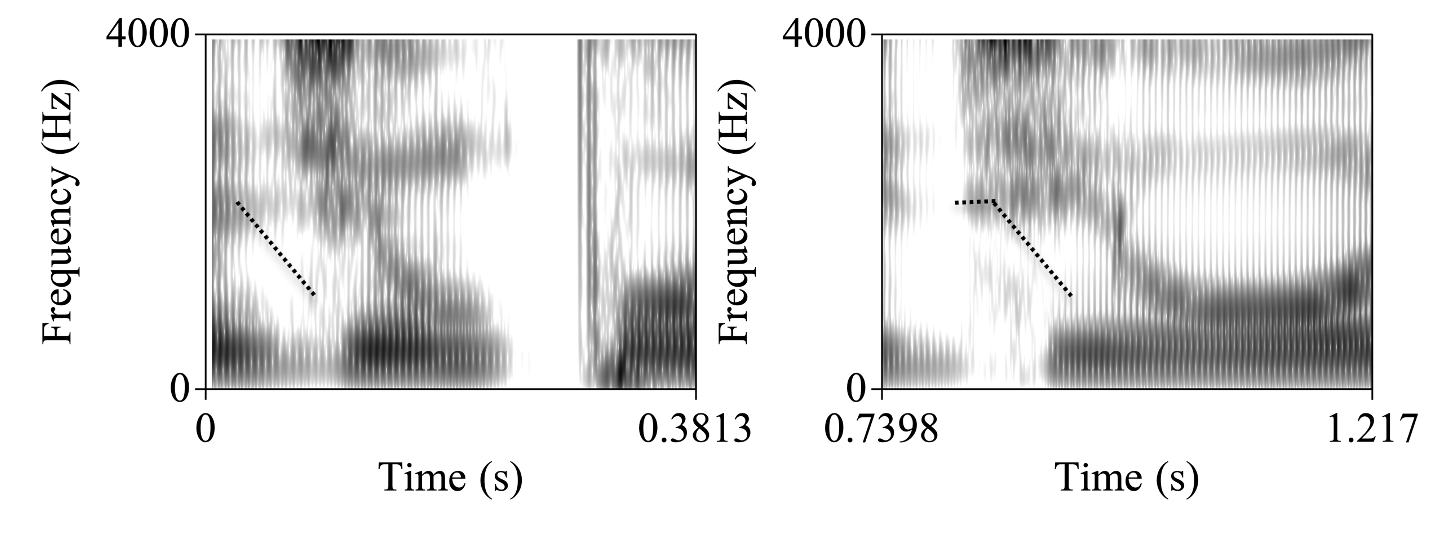
Figura 3: Espectrogramas de uma produção ditongada da sequência "de um" (esquerda) e não ditongada da sequencia "de ou(ro)". As linhas assinalam os movimentos de F2.
Bibliografia básica
BARBOSA, P. A; ALBANO, E. C. Brazilian Portuguese. Illustrations of the IPA. Journal of the International Phonetic Association, 34 (2): 227-232, 2004.
CALLOU, D.; LEITE, Y. Iniciação à fonética e à fonologia. 8a. ed. Rio de Janeiro: Jorge Zahar Editora, 2001.
CÂMARA Jr., J. M. Estrutura da língua portuguesa. 7. ed. Petrópolis, RJ: Editora Vozes, 1976.
Bibliografia avançada
BARBOSA, P. A. Do grau de não perifericidade da vogal /a/ pós-tônica final. Diadorim (Rio de Janeiro), 12, 91-107, 2012.
BARBOSA, P. A.; MADUREIRA, S. Manual de Fonética Acústica Experimental. Aplicações a dados do português. São Paulo: Cortez, 2015.