É parte fundamental das ciências da fala a investigação das funções sensoriais e cognitivas que possibilitam a percepção da fala. Os processos envolvidos são diversos, como a extração de informação sensorial – não apenas auditiva, mas, comumente, multimodal (v. Fala e multimodalidade); a análise da cena auditiva para a segregação e integração de informações associadas a diferentes fontes sonoras (e.g., imagine-se em uma festa atentando à fala de um interlocutor em meio ao burburinho e, ao mesmo tempo, seguindo com os pés o ritmo da música); o mapeamento do sinal da fala em unidades que compõem o conhecimento da língua, promovendo o reconhecimento da mensagem linguística, sempre misturada a vários outros tipos de informação de relevância comunicativa e comportamental (como bem observa Plínio Barbosa, v. Ciências da fala). Tais processos compõem uma hierarquia complexa de processamento perceptivo, com fluxos bidirecionais de informação (da base para o topo e vice-versa), continuamente dedicada a modelar as causas das entradas sensoriais (e.g., sons que perturbam estruturas orelha adentro), ou seja, perceber objetos e eventos no mundo. Esta hierarquia é implementada em populações de neurônios no encéfalo cuja atividade pode ser, ao menos parcialmente, medida na superfície da cabeça por meio de técnicas como a eletroencefalografia. Isto nos proporciona acesso empírico ao processamento sensorial e cognitivo. É esse tipo de medida que descrevo aqui.
Em estruturas encefálicas como o córtex cerebral, a atividade sincronizada de grandes populações de neurônios alinhados entre si gera variações de tensão elétrica suficientemente intensas para serem detectadas por eletrodos posicionados na superfície da cabeça. O registro dessas ondas elétricas é denominado eletroencefalograma (EEG); o registro do campo magnético associado, magnetoencefalograma (MEG). Uma das mais antigas técnicas de registro de atividade neural, a eletroencefalografia segue amplamente empregada em ciências cognitivas, particularmente em estudos que buscam observar o processamento em seu curso no tempo. Isto porque a resolução temporal do EEG (e do MEG) é excelente em comparação a outras técnicas, permitindo acessar eventos neurais que se desenvolvem em intervalos muito curtos, na ordem dos milissegundos. Por outro lado, quanto às possibilidades de se localizar a(s) fonte(s) geradora(s) da atividade medida por EEG, a resolução espacial é bastante limitada – em comparação, por exemplo, ao Imageamento por Ressonância Magnética Funcional (fMRI) que, por sua vez, oferece baixa resolução temporal. Como os tecidos entre os geradores neurais de atividade e a superfície da cabeça são transparentes aos campos magnéticos, o MEG proporciona uma resolução espacial superior à do EEG, embora não comparável à do fMRI.
No campo das investigações da percepção da fala, predomina o método experimental. De modo geral, trata-se de testar hipóteses deduzidas a partir de formulações teóricas e operacionalizadas como previsões acerca dos efeitos de manipulações sistemáticas e controladas de determinados fatores (“variáveis independentes”) sobre medidas admitidas como índices dos processos perceptivos investigados (“variáveis dependentes”; v. Estatística). Medidas baseadas em respostas comportamentais – como a proporção de uma alternativa de resposta em uma tarefa, ou o tempo entre um estímulo e a resposta – são amplamente empregadas como variáveis dependentes. Como um exemplo simples, poderíamos verificar se a proporção de respostas “i” em uma tarefa de classificação de vogais dada a um grupo de participantes varia sistematicamente em função de uma manipulação da frequência fundamental (F0) dos sons vocálicos usados como estímulos na tarefa. É fundamental delinear cuidadosamente o experimento para que a medida reflita a função perceptiva investigada. Porém, a resposta comportamental resulta também da orquestração de processos associados a outras várias funções, como motivação, controle executivo, tomada de decisão, seleção e preparação motora da resposta. É, portanto, de grande interesse que a pesquisa baseada em medidas comportamentais seja complementada por experimentos que tenham, como variáveis dependentes, medidas mais diretas do funcionamento neural; que se justifiquem enquanto manifestações de processos mais específicos. Portanto, para além das oportunidades de estudo das bases neurobiológicas, trata-se de obter medidas que sirvam ao propósito de testar modelos de processamento da fala, inclusive em níveis abstratos em que não há referência à implementação neural.
Os registros de EEG e MEG oferecem possibilidades múltiplas de obtenção de medidas do processamento neural. Assim como os trechos de fala na fonética acústica, os trechos de EEG ou MEG podem ser analisados no domínio do tempo e no domínio das frequências (Figura 1). No primeiro, as magnitudes são descritas em função do tempo. A cada ponto no tempo associa-se um valor como, por exemplo, a amplitude da tensão elétrica. Obtém-se assim séries temporais que podem ser exploradas como índices do decurso do processamento em diferentes etapas. No domínio das frequências[1], magnitudes (e/ou fases das componentes ondulatórias) são descritas em função das frequências em um espectro, o que permite explorar a atividade oscilatória de populações neurais em diferentes faixas de comprimento de onda, ou seja, de ritmos mais lentos a mais rápidos, como nas clássicas bandas de frequência do EEG: delta (até ∼4 Hz), teta (∼4 – 8 Hz), alfa (∼8 – 12 Hz), beta (∼12 – 30 Hz) e gama (acima de ∼30 Hz). Há ainda técnicas de análise tempo-frequência, que permitem examinar, em espectrogramas, como a atividade neural oscilatória em diferentes frequências evolui no tempo.
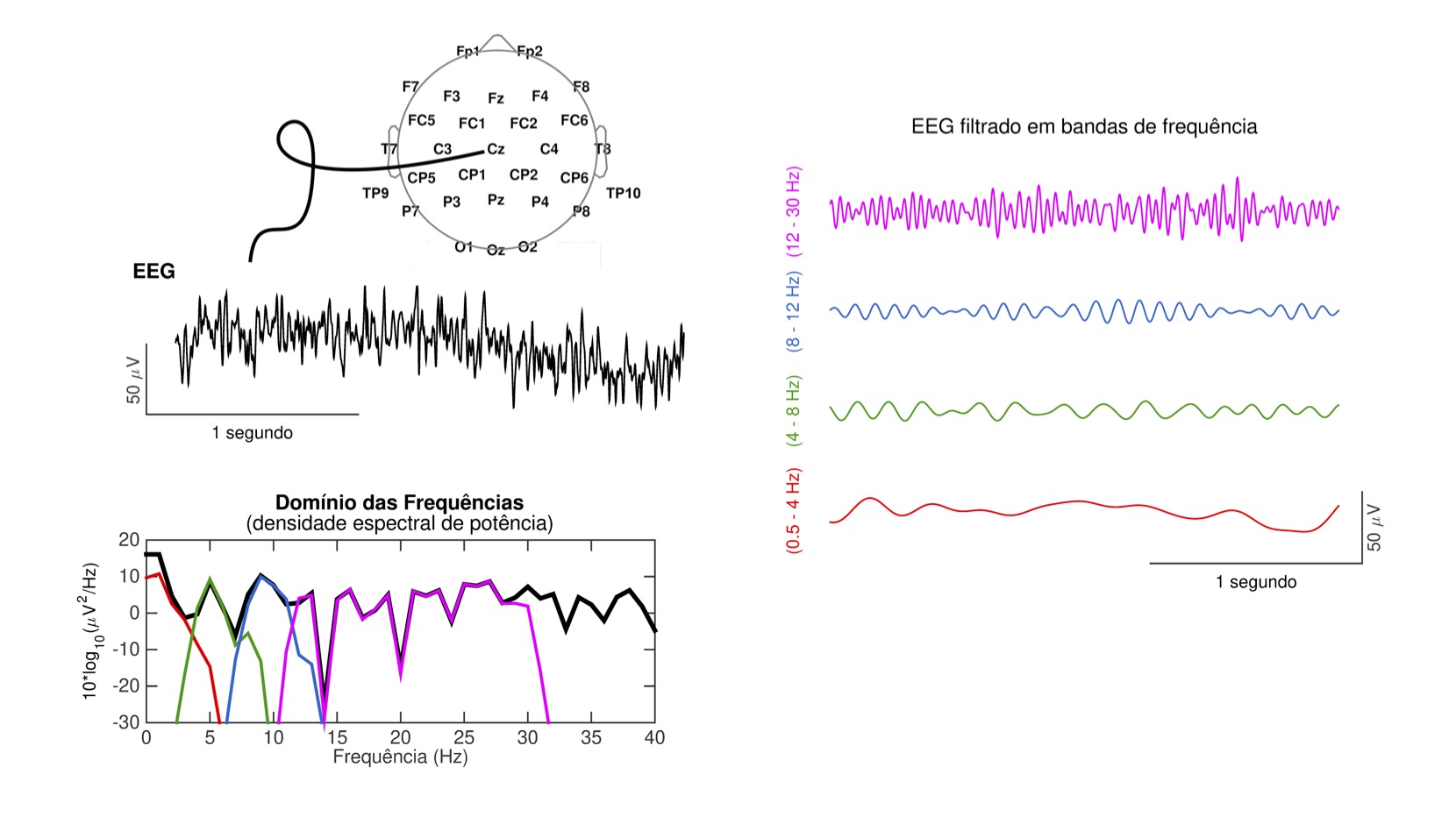
Figura 1. À esquerda, um trecho de eeg registrado na posição do vértice da cabeça (Cz), representado no domínio do tempo e das frequências. À direita, o mesmo trecho após filtragem em quatro bandas de frequência.
De volta ao domínio do tempo, uma classe de medidas há muito consolidada é a dos potenciais relacionados a eventos (ERP), que consistem em variações no EEG associadas a eventos sensoriais, cognitivos ou motores – como a apresentação de um estímulo, a violação de uma expectativa, ou o pressionamento de um botão. Considere, por exemplo, uma pessoa que ouve uma sequência de apresentações repetidas de um som. Cada apresentação desencadeia um fluxo complexo de modulações da atividade neural através dos diversos níveis do sistema auditivo, e além. Parte desta atividade afeta o EEG, mas seu efeito é tão pequeno que desaparece em meio ao ruído[2]. A maneira mais comum de tornar esse efeito visível e mensurável é calcular a chamada “média coerente” entre dezenas ou centenas de trechos de EEG. Cada trecho corresponde a um intervalo fixo de tempo com referência a uma ocorrência do evento (e.g., de 100 ms antes a 600 ms após o início do estímulo sonoro). O traçado resultante da média entre esses trechos é o ERP (em casos como este, em que se mede a resposta a um estímulo auditivo, usa-se também o termo potencial evocado auditivo). O termo campo relacionado a evento (ERF) designa o resultado do mesmo procedimento quando aplicado sobre trechos de MEG; o termo respostas relacionadas a eventos se refere a ambos.
Gerado por ondas de atividade sincronizada em resposta a sons ao longo de toda a via neural auditiva, do nervo auditivo ao córtex cerebral, o traçado do ERP auditivo é formado por sucessivas deflexões de tensão, com polaridades positivas e negativas (Figura 2). Normalmente o ERP é dividido em componentes – i.e., partes tratadas como distintas e separáveis – cada qual caracterizado por seu curso no tempo, sua polaridade e sua topografia, ou seja, o modo como se distribui entre eletrodos em diferentes posições. Essas respostas podem ser agrupadas em três grandes classes: respostas de troco encefálico, respostas de latência média e respostas de latência longa. As respostas de tronco encefálico ocorrem dentro dos primeiros ∼10 ms após o início do estímulo, sendo geradas em estruturas subcorticais no tronco cerebral e tálamo. São respostas transientes a descontinuidades sonoras, como o ruído de plosão de uma consoante oclusiva, o início ou o fim de uma vogal. Para sons periódicos, são seguidas por uma resposta sustentada, sincronizada em fase com sua estrutura temporal, seguindo F0 e harmônicos mais baixos. Essas respostas são exploradas em estudos da representação e processamento subcortical do sinal da fala, incluindo suas características acústicas de fonte e filtro e efeitos da experiência (e.g., musical ou com línguas tonais; Chandrasekaran & Kraus, 2010). A resposta de latência média tem fontes no córtex auditivo, e se apresenta geralmente como uma sequência de cinco deflexões negativas e positivas, com picos entre 10 e 50 ms após o início do estímulo. Para taxas mais rápidas de estimulação, ou sons modulados em frequência ou amplitude, as respostas se coadunam em uma resposta periódica, denominada resposta auditiva em regime permanente, cuja frequência corresponde à frequência de modulação da estimulação (não há uma distinção clara entre esta e a resposta sustentada a sons periódicos mencionada acima). As respostas de latência longa refletem etapas já avançadas do processamento auditivo, principalmente no córtex cerebral. Seus componentes mais proeminentes, P1, N1 e P2, são declinações cujos picos apresentam latências por volta de 50, 100 e 200 ms após o início do estímulo. No ERP obtido na região do vértice da cabeça, a primeira e a terceira têm polaridade positiva; a segunda, negativa – daí as letras “P” e “N” na nomenclatura. Essas respostas são classificadas como “obrigatórias”, por serem eliciadas tanto por estímulos irrelevantes como por estímulos relevantes, sejam ignorados ou colocados sob foco da atenção. Tipicamente, P1, N1 e P2 apresentam topografia fronto-central, com inversão de polaridade na região do processo mastoide[3] – consistente com geradores localizados no córtex auditivo.
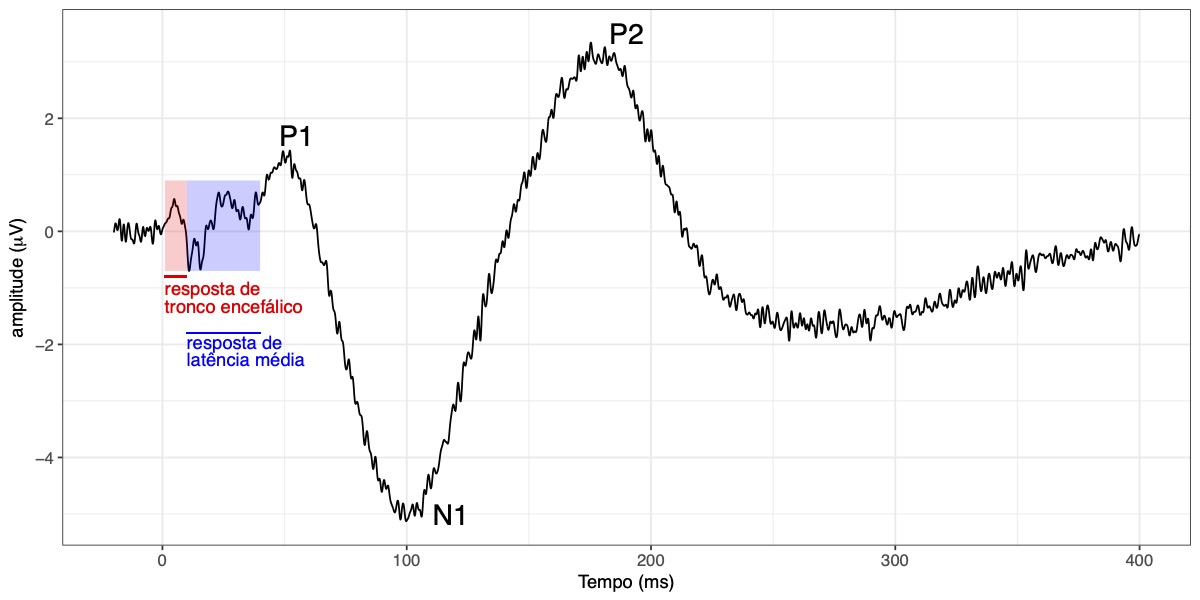
Figura 2. ERP auditivo típico de registros na região do vértice da cabeça (gerado a partir de dados fictícios, com propósitos ilustrativos).
Entre as respostas auditivas obrigatórias, a mais estudada no campo da percepção da fala é N1. Atualmente, considera-se que ao menos três subcomponentes associados a processos distintos, contribuem para o pico negativo identificado como N1. Em seu influente modelo, Näätänen e Picton (1987) propõem um subcomponente gerado por processos de análise de propriedades acústicas na porção supratemporal do córtex auditivo, um outro que refletiria estágios mais avançados do processamento na porção lateral do córtex auditivo, e um terceiro, com geradores em áreas não específicas à modalidade auditiva, associado à detecção de transientes acústicos e à orientação involuntária da atenção provocada pelos mesmos. Resultados de tentativas de se localizar fontes de N1 no córtex auditivo sugerem mapeamentos consistentes de vogais e de consoantes na superfície cortical ao longo de dimensões acústicas ou fonéticas (Manca et al., 2019). A natureza dessas dimensões (e.g., se correspondem a propriedades acústicas gerais, a categorias fônicas ou a traços distintivos) necessita ainda ser elucidada. Com base na literatura e em uma decomposição estatística do complexo N1-P2 em resposta a sons vocálicos de um continuum entre as categorias [i] e [e], Silva, Rothe-Neves e Melges (2020b) propõem a) que geradores neurais de N1 em torno de 100 ms após o início do estímulo refletem o processamento auditivo geral de informação psicoacústica, b) que o processamento de informação sobre categorias fônicas emerge posteriormente, por volta dos 140 ms, e c) que a atividade no intervalo em torno do pico de P2 pode envolver o processamento paralelo de informações que compõem uma representação perceptiva unitária da vogal em seu duplo aspecto: enquanto categoria discreta (/e/, por exemplo) e enquanto som particular, discriminável de outros exemplares de sua categoria.
Outro componente dos ERPs muito usado nas investigações da percepção da fala é a “negatividade de incongruência” (Mismatch Negativity; doravante, MMN), uma resposta a estímulos “desviantes”, isto é, a violações de alguma regularidade estabelecida por uma sequência repetitiva ou previsível de sons “padrão”. Comparado ao ERP para os estímulos padrão, o ERP para os desviantes é mais negativo em uma janela de tempo que abrange parte do complexo N1-P2. Por isso, é comum que se subtraia a resposta ao estímulo padrão da resposta ao desviante para facilitar a visualização e análise, gerando uma “onda de diferença” em que a MMN se apresenta como uma deflexão negativa com pico entre 150 e 250 ms após o estímulo desviante, e topografia fronto-central. De acordo com a interpretação predominante, regularidades na sequência de estímulos padrão são extraídas e representadas na memória auditiva, estabelecendo previsões a respeito dos estímulos por vir; quando um estímulo diverge dessas previsões, a MMN é gerada no córtex auditivo e áreas frontais, como uma espécie de sinal de erro. Como a MMN é comumente obtida em condições passivas de estimulação – em que o participante é instruído a ignorar os estímulos auditivos enquanto realiza alguma atividade, como assistir a um filme mudo ou ler um texto – considera-se que esta resposta reflete processos automáticos de discriminação auditiva (que permitem distinguir os desviantes em meio aos estímulos padrão).
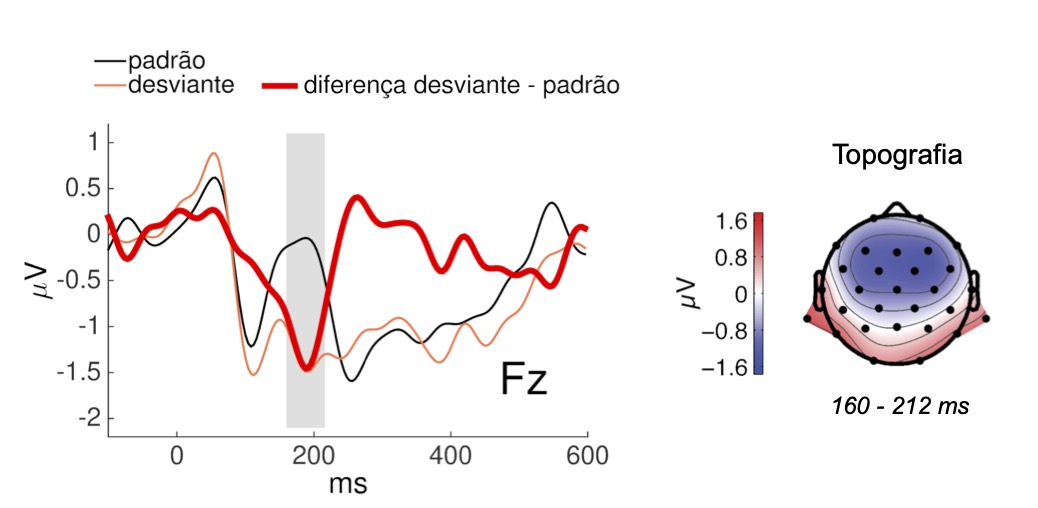
Figura 3. MMN: o traçado em vermelho mostra a onda de diferença entre as respostas a uma vogal [e] apresentada como estímulo desviante e à mesma vogal apresentada como estímulo padrão. À direita, a topografia da MMN (amplitude média no intervalo 160 – 212 ms, marcado em cinza). Adaptado de Silva, Melges e Rothe-Neves (2017).
Um exemplo interessante é o estudo em que Lu, Vigário e Frota (2018) examinaram a percepção do acento em falantes do português europeu na ausência das diferenças de qualidade vocálica entre átonas e tônicas – cruciais naquela língua para a identificação do acento. Enquanto o padrão de desempenho comportamental em uma tarefa de discriminação entre dissílabos paroxítonos e oxítonos foi caracterizado como uma “surdez verbal para o acento”, comparável ao de falantes de línguas com acento fixo, a discriminação perceptiva automática, manifesta na MMN, apresentou-se aparentemente preservada. Outra propriedade particularmente relevante da MMN é sua sensibilidade a efeitos da experiência linguística e a padrões específicos à língua (inclusive em bebês; CHEOUR et al., 2001). Uma observação recorrente em estudos da MMN em resposta a sons da fala é que sua amplitude é maior quando a diferença acústica entre os estímulos padrão e desviante corresponde a um contraste distintivo na língua do participante, em comparação a condições em que a mesma diferença acústica não é fonologicamente funcional. Em estudo recente, observou-se ainda uma supressão da MMN associada à neutralização fonológica do contraste entre vogais médias altas e médias baixas em sílabas átonas do português brasileiro, revelando um correlato perceptivo da fusão entre categorias fonêmicas neutralizadas, como as átonas [e] e [ɛ] em português (SILVA; ROTHE-NEVES, 2020a). Vale notar que, embora seja uma resposta ao desviante, a MMN permite explorar a informação na memória auditiva sobre as regularidades que definem a sequência de estímulos padrão, através dos padrões de variação de amplitude e/ou latência em função do tipo e grau de disparidade entre os estímulos desviantes e o que poderia ser previsto a partir dos estímulos padrão. Assim, é possível investigar representações linguísticas dos mais diversos tipos através da MMN, desde que se possa gerar sequências de estímulos padrão previsíveis (seja por simples repetição ou por seguirem regularidades) entremeadas por estímulos desviantes ocasionais.
Vários outros componentes do ERP auditivo são úteis ao estudo da percepção da fala. Por exemplo, um componente denominado P3a pode ocorrer após a MMN. O P3a é associado à orientação da atenção pelo desviante quando este é suficientemente saliente e identificado como “novidade”. Se o estímulo desviante for um estímulo “alvo” em uma tarefa, ocorre também o P3b, precedido pelo N2b (sobreposições entre estes e P3a e MMN dificultam a identificação dos componentes em tais circunstâncias). Há também técnicas mais sofisticadas de análise da atividade neural relacionada a eventos, como análises de tempo-frequência que permitem observar como oscilações neurais em frequências diversas variam ao longo de um intervalo de tempo em resposta a um dado evento (e.g., um estímulo).
Pesquisadores em psicolinguística e neurociências da percepção e da linguagem se valem também de medidas derivadas de um conjunto de fenômenos, designados pelo termo “neural entrainment”, em que fontes de atividade neural manifesta no EEG/MEG entram em sincronia com periodicidades presentes nos estímulos, revelando interações entre processos internos e a entrada sensorial. Durante a apresentação de sinais acústicos com estrutura rítmica, como fala e música, é possível observar aumentos seletivos de atividade neural em frequências que descrevem ritmos no estímulo, e também alinhamentos de oscilações neurais (inclusive em outras frequências) a elementos rítmicos – por exemplo, por reajustes em suas fases. Medidas desse tipo de atividade são comumente obtidas e analisadas no domínio das frequências, incluindo técnicas para explorar a intensidade da atividade neural nas frequências de interesse, e para explorar a coerência entre as fases das oscilações neurais e os estímulos. Uma observação interessante é a de que processos geradores de atividade neural podem entrar em sincronia mesmo com elementos rítmicos gerados internamente pelo ouvinte, mesmo na ausência de informação acústica. Por exemplo, uma pessoa que ouve cliques idênticos sucessivos, apresentados a uma taxa de 2,4 por segundo, pode, a seu bel-prazer, perceber um ritmo ternário (como na valsa: ...1...2...3...1...2...3...), com 0,8 ciclo por segundo, ou um ritmo binário (como, tipicamente, no samba: ...1...2...1...2...1...2...), com 1,2 ciclo por segundo. Em casos assim, a estrutura métrica é, pode-se dizer, “imaginada”. Não tem correlatos físicos no estímulo acústico, mas é gerada internamente e imposta pelo sistema perceptivo. Aumentos seletivos de atividade no EEG são observados nas frequências correspondentes à estrutura métrica percebida, diferindo consistentemente entre as duas alternativas, ainda que, fisicamente, os estímulos sejam sempre os mesmos (Nozaradan et al., 2011).
Há muito ainda a se investigar sobre a natureza dessas respostas, para as quais diferentes tipos de mecanismos poderiam contribuir em graus variados. Um deles envolve a simples coadunação de ERPs, ou respostas relacionadas a eventos sucessivos no estímulo, formando uma resposta em regime permanente (como mencionado na seção precedente) linearmente sobreposta ao EEG “de fundo”. Outro tipo de mecanismo envolve um acoplamento de oscilações neurais já em curso, que compõem o EEG de fundo, a estruturas temporais no estímulo ou internamente geradas. Seja em repouso ou durante qualquer atividade, o EEG/MEG registra oscilações neurais em múltiplas frequências, tradicionalmente divididas as bandas delta, teta alfa, beta e gama. Essas ondas capturam a atividade oscilatória sincronizada de grandes populações de neurônios em redes distribuídas no cérebro. A significação funcional dessas oscilações e do modo como elas variam em função de diversos fatores, assim como os mecanismos subjacentes, são atualmente objeto de intenso debate e esforço científico.
O sinal acústico da fala é modulado em várias frequências, formando uma envoltória temporal complexa (que representa as variações do sinal no tempo excluindo a estrutura fina), com modulações associadas à organização temporal de segmentos, sílabas e padrões prosódicos (v. Fonologia da Prosódia). Como se poderia esperar a partir dos parágrafos acima, essas modulações em múltiplos níveis da organização sonora provocam modulações correspondentes de atividade no cérebro do ouvinte, em múltiplas faixas de frequência. Mesmo na ausência de informação acústica sobre níveis de organização acima da sílaba, observa-se sincronização de atividade neural não apenas à taxa silábica, mas também a estruturas hierárquicas abstratas que agrupam, “na mente” do ouvinte, as sílabas em unidades linguísticas como sintagmas e sentenças (Ding et al., 2017). Atualmente, medidas desse tipo de “entrada em sincronia” da atividade neural são amplamente empregadas no estudo da percepção auditiva e audiovisual da fala, do processamento da linguagem e do papel de estruturas linguística, funções cognitivas e fatores associados ao desenvolvimento humano.
Chandrasekaran, B., & Kraus, N. (2010). The scalp‐recorded brainstem response to speech: Neural origins and plasticity. Psychophysiology, 47(2), 236-246.
Cheour, M., Korpilahti, P., Martynova, O., & Lang, A. H. (2001). Mismatch negativity and late discriminative negativity in investigating speech perception and learning in children and infants. Audiology and Neurotology, 6(1), 2-11.
Ding N, Melloni L, Yang A, Wang Y, Zhang W and Poeppel D (2017) Characterizing Neural Entrainment to Hierarchical Linguistic Units using Electroencephalography (EEG). Frontiers in Human Neuroscience, 11:481.
Lu S, Vigário M, Correia S, Jerónimo R and Frota S (2018) Revisiting Stress “Deafness” in European Portuguese – A Behavioral and ERP Study. Front. Psychol. 9:2486.
Manca, A. D. et al. Electrophysiological evidence of phonemotopic representations of vowels in the primary and secondary auditory cortex. Cortex, v. 121, p. 385–398, dez. 2019.
Näätänen, R.; Picton, T. The N1 wave of the human electric and magnetic response to sound: a review and an analysis of the component structure. Psychophysiology, v. 24, n. 4, p. 375–425, jul. 1987.
Nozaradan, S., Peretz, I., Missal, M., & Mouraux, A. (2011). Tagging the neuronal entrainment to beat and meter. Journal of Neuroscience, 31(28), 10234-10240.
Silva D. M. R.; Melges, D. B.; Rothe-Neves, R. N1 response attenuation and the mismatch negativity (MMN) to within- and across-category phonetic contrasts. Psychophysiology, v. 54, n. 4, p. 591–600, abr. 2017.
Silva, D. M. R.; Rothe-Neves, R. Context-dependent categorisation of vowels: a mismatch negativity study of positional neutralisation. Language, Cognition and Neuroscience, p. 1–16, jul. 2020a.
Silva, D. M. R.; Rothe-Neves, R.; Melges, D. B. Long-latency event-related responses to vowels: N1-P2 decomposition by two-step principal component analysis. International Journal of Psychophysiology, v. 148, p. 93–102, fev. 2020b.
Luck, S. J. (2014). An introduction to the event-related potential technique. MIT press.
Silva, D. M. R., & Rothe-Neves, R. (2014). Respostas evocadas de incongruência a categorias na percepção da fala. Letras de Hoje, 49(1), 66-75.
Silva, D. M. R. (2020) Potenciais relacionados a eventos no estudo da percepção da fala e da organização sonora da linguagem. In C. S. F. Oliveira, & T. M. Machado de Sá (Orgs.). Psicolinguística em Minas Gerais. CEFETMG
Ding, N., Melloni, L., Zhang, H., Tian, X., & Poeppel, D. (2016). Cortical tracking of hierarchical linguistic structures in connected speech. Nature neuroscience, 19(1), 158-164.
Myers, B. R., Lense, M. D., & Gordon, R. L. (2019). Pushing the envelope: Developments in neural entrainment to speech and the biological underpinnings of prosody perception. Brain sciences, 9(3), 70.
Manca, A. D; Grimaldi, M. Vowels and Consonants in the Brain: Evidence from Magnetoencephalographic Studies on the N1m in Normal-Hearing Listeners. Frontiers in Psychology, v. 7, 2016.
MONAHAN, P. J. Phonological Knowledge and Speech Comprehension. Annual Review of Linguistics, v. 4, n. 1, p. 21–47, 2018.
Notas
[1] Qualquer sinal que se dá no tempo, como sons e registros de EEG, pode ser decomposto em componentes ondulatórias que descrevem oscilações periódicas simples, cada qual caracterizada por sua amplitude, sua frequência e sua fase. A amplitude expressa o “tamanho” da componente. A frequência corresponde ao número de ciclos de oscilação por unidade de tempo (e.g., ciclos por segundo ou Hertz). A fase é a propriedade pela qual duas ondas simples com frequência e amplitude idênticas podem diferir, expressando o ponto do ciclo quem que a onda se encontra em um dado ponto no tempo.
[2] Por “ruído”, entenda-se toda e qualquer variação de tensão no EEG que não interessa como objeto de observação.
[3] Isto depende, na verdade, da posição do eletrodo de referência, que fornece a linha de base a partir da qual os valores de tensão são medidos nos outros eletrodos. Uma posição de referência muito usada é a ponta do nariz.